Streaming jobs perform well under constant load. But what happens when you need to look backward?
Streaming jobs—especially Flink-basedApache Flink is an open-source framework for distributed stream processing. It processes data continuously as it arrives, rather than in batches. ones—perform well under constant load. At real-time scale, throughput is bounded by input rate: you can only produce as fast as data arrives.
Example: Imagine a streaming pipelineA streaming pipeline is a chain of data processing steps that operate on continuous data flows. Data enters at one end (sources), flows through transformations (filters, aggregations, joins), and exits at the other end (sinks). that analyzes payment transactions to detect fraud in real-time. It examines each user's recent history and flags suspicious patterns. Now suppose the fraud team ships a new detection algorithm—one that's smarter, catches more edge cases. To roll it out cleanly, you need a consistent view: re-run the new algorithm over the last three months of transactions and produce a fresh set of flagged users.
You want to backfill historical data, then seamlessly swap over to real-time processing with minimal downtime. This backs a production system—the backfillA backfill is the process of reprocessing historical data to populate or update a system. Common reasons include fixing bugs, deploying new algorithms, or recovering from data corruption. needs to happen fast.
That's not real-time anymore. That's backfill. And suddenly you're asking: where do three months of transactions actually live?
Why not Kafka (long-term storage)
KafkaApache Kafka is a distributed event streaming platform. It stores streams of records in categories called "topics," which are split into partitions for parallelism. wasn't designed to be a long-term data store. Retention policiesKafka can be configured to delete records after a certain time (e.g., 7 days) or when the topic exceeds a size limit. This prevents unbounded storage growth. exist for a reason—keeping months or years of data in Kafka means brokerKafka brokers are the servers that store data and serve client requests. A Kafka cluster typically has multiple brokers for fault tolerance. storage costs explode, rebalancing becomes painfully slow, and recovery times balloon as brokers reload massive log segments.
So we archive. Cold data moves to cheap object storageObject storage services like Amazon S3, Google Cloud Storage (GCS), and Hadoop Distributed File System (HDFS) store data as "objects" rather than files in a hierarchy. They're optimized for durability and cost, not low-latency access.—S3, GCS, HDFS—where it sits until we need it again.
How archiving works
The typical pattern is straightforward: a background process tails"Tailing" means continuously reading new records as they arrive, similar to the Unix `tail -f` command that follows a file as it grows. Kafka partitionsA Kafka partition is an ordered, immutable sequence of records. Topics are divided into partitions to enable parallel processing—each partition can be read by a different consumer., batches records into files (Avro, ParquetAvro and Parquet are columnar file formats optimized for big data. They provide efficient compression and fast reads for analytics workloads., or raw), writes them to blob storage, and deletes from Kafka once persisted. Each file represents a chunk of time or a transaction boundary—indexed so you can find "all data from partition 3 between timestamps X and Y."
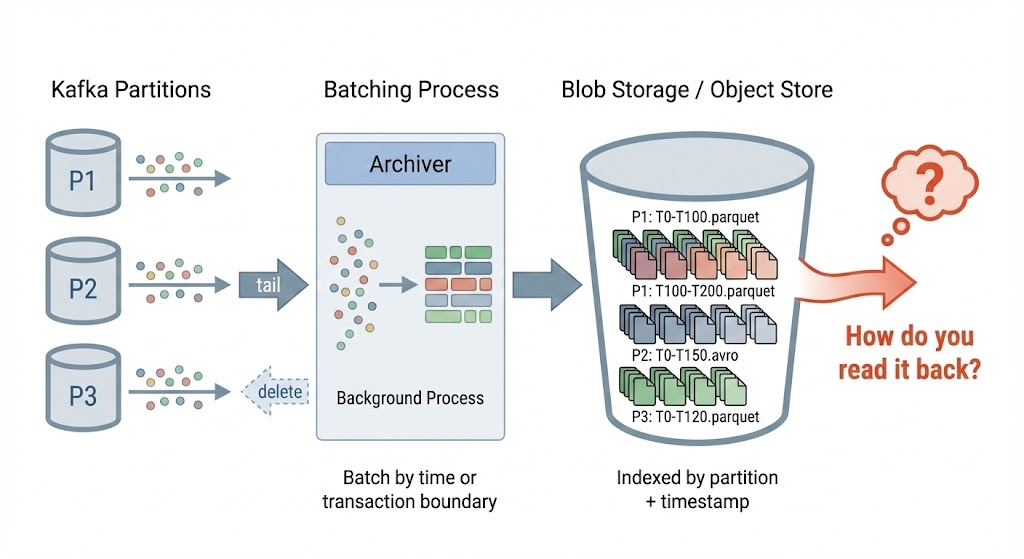
This works great for writes. The archive grows quietly in the background, cheap and durable.
The question is: how do you read it back?
Why historical backfill can't scale beyond partition count
Here's the fundamental constraint: your maximum read parallelism equals your Kafka partition count.
If your topic has 8 partitions, you get 8 parallel readers. Why? Because each partition's archive is a single logical stream. Records within a partition must be read in order to preserve per-key ordering guaranteesKafka guarantees that records with the same key always go to the same partition, and within a partition, records are strictly ordered. This means if you send events A→B→C for user "alice", they'll always be read in that order.. One reader per partition. No exceptions.
This wouldn't be so bad if partition counts were large. But in practice, Kafka partition counts are often small—3, 8, maybe 16. There is a tradeoff to having too many partitions: more partitions mean slower rebalancesWhen consumers join or leave a Kafka consumer group, partitions must be redistributed among the remaining consumers. This "rebalancing" pauses processing temporarily—more partitions means longer pauses., more leader electionsEach Kafka partition has one "leader" broker that handles all reads/writes. When a broker fails, a new leader must be elected. More partitions means more elections during failures., more extreme partition skew, etc.
So your three-month backfill is bottlenecked by 8 readers crawling through archive files sequentially.
Why sharding readers doesn't solve the problem
A natural response is to shard the workload: assign multiple readers to the same partition's archive, each responsible for a subset of keys. Reader A processes keys A-M, Reader B handles N-Z. In theory, this doubles throughput.
In practice, sharding readers across an unindexed archive creates a different problem: I/O amplificationI/O amplification occurs when a system reads (or writes) more data than logically necessary. If you need 10 GB of data but must read 100 GB to get it, that's 10× I/O amplification..
I/O Amplification with Sharded Readers
Partition 3 Archive File (100 GB):
+-------------------------------------------------------------+
| [key_alice] [key_bob] [key_alice] [key_charlie] [key_bob] |
| [key_dave] [key_alice] [key_eve] [key_charlie] [key_bob] |
| ... (billions of interleaved records) ... |
+-------------------------------------------------------------+
Reader A (keys A-M): Reads 100 GB, keeps ~50 GB, discards ~50 GB
Reader B (keys N-Z): Reads 100 GB, keeps ~50 GB, discards ~50 GB
-----------------------------------------
Total I/O: 200 GB (2x the file size!)Both readers must scan the entire file, resulting in 2× I/O
Both readers must scan the entire file. Without an index mapping keys to byte offsets, there's no way to seek directly to relevant records. The archive is a sequential log of transactions with keys interleaved throughout. Each reader reads everything, filters for its shard, and discards the rest.
The result: N shards means N times the I/O with no change to throughput, not N times throughput.
The irreducible bottleneck
Streaming pipelines are bottlenecked by their slowest stage. So maybe large-scale backfill is just inherently slow and expensive—something we have to accept?
It is expensive. But here's the critical distinction: most bottlenecks can be solved by throwing resources at them.
If your slow stage is a downstream transform—complex aggregations, ML inference, a slow sinkA "sink" is the final destination where processed data is written—a database, file system, or another streaming system.—you can scale it. Add more task managersIn Flink, a TaskManager is a worker process that executes parts of your streaming job. Adding more TaskManagers lets you run more parallel instances of your operators.. Provision bigger machines. These bottlenecks are solvable because you control the parallelism.
The source is different. Source parallelism is fixed by the partition count. Eight partitions means eight readers—period. It doesn't matter if you have 100 task managers or 1,000 CPU cores. The partition count is a hard constraint that no amount of provisioning can change.
This makes source backfill the irreducible bottleneck. Once you've optimized everything else—scaled your transforms, tuned your sinks, parallelized your aggregations—the source becomes the ceiling.
Any solution that doesn't increase true source parallelism is rearranging deck chairs.
Reframing: what guarantees do we actually need?
At this point it's worth stepping back. The standard backfill architecture has an implicit dependency baked in: it preserves per-partition ordering—the same ordering Kafka provides. But does our application actually need this?
Streaming applications don't actually care about partition ordering. A fraud detection pipeline doesn't need Alice's transactions to interleave with Bob's in any particular way. It only needs Alice's transactions to arrive in order relative to each other. The same is true for Bob, and Charlie, and every other user.
Per-key ordering—not per-partition ordering—is what matters. Per-partition ordering is strictly stronger, and that unnecessary strictness is exactly what creates the scalability bottleneck.
This reframing opens up new possibilities. If we only need per-key ordering, we're free to reorganize the archive—split partitions, merge partitions, reorder across keys—as long as records for each key remain in sequenceSequence preservation means if Alice's events were originally A→B→C→D, they must still appear in that order after reorganization. The events can be interleaved with Bob's events differently than before, but Alice's relative order is sacred..
The second constraint: time coordination
Per-key ordering is necessary. But it's not sufficient. There's another constraint streaming systems must respect: coordinated time progression.
Streaming pipelines use watermarksA watermark is a special marker that says "all events with timestamps before this point have arrived." It's how streaming systems know when it's safe to finalize computations that depend on time, like "count events in the last 5 minutes." to track event-timeEvent time is when something actually happened (e.g., when a user clicked a button). This differs from processing time, which is when the system processes the record. Event time lets you handle out-of-order and delayed data correctly. progress. Watermarks drive critical behaviors: evicting windowsWindowing groups records by time ranges (e.g., "all events in each 5-minute interval"). When a watermark passes a window's end time, the window is "evicted"—its results are emitted and its state is cleared., firing timers, and filtering late-arriving records. When a watermark advances to time T, the system assumes all records with timestamps before T have arrived. Records that show up after? They're "late"—often dropped or routed to a side outputA side output is a secondary stream where you can send records that don't fit the main flow—late data, errors, or records that need special handling. It's like an "exception lane" that keeps the main pipeline clean..
Now consider what happens with one-file-per-key (or any scheme where keys are read independently at different rates):
Watermark Progression Problem
Key B races ahead, advances the watermark, and Key A's valid data gets discarded
The problem isn't ordering—Key A's records are still in order. The problem is that Key B raced ahead, advanced the watermark, and declared Key A's data late before it even arrived.
Per-key ordering preserves correctness within a key. Time coordination preserves correctness across keys.
Any solution must address both. Key groups handle the first constraint. For the second, we'll need synchronization points—barriers where all readers pause and wait for the slowest before proceeding.
Key groups: the right abstraction
With these two constraints clear—per-key ordering and time coordination—the solution becomes clear. Create virtual buckets—called key groups—that sit between "one file" and "one file per key."
Key Groups: The Goldilocks Tradeoff
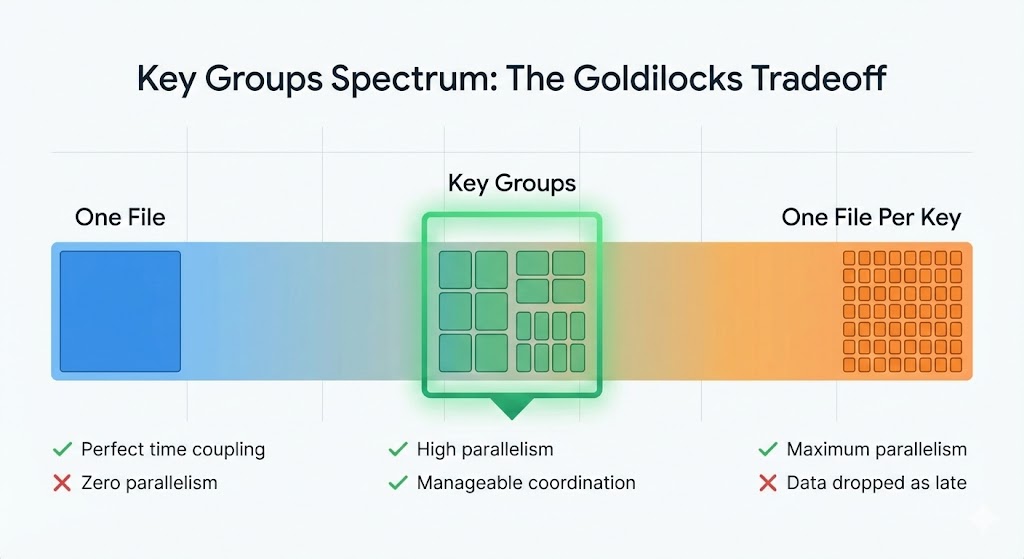
Key groups provide the best of both worlds: high parallelism with manageable coordination
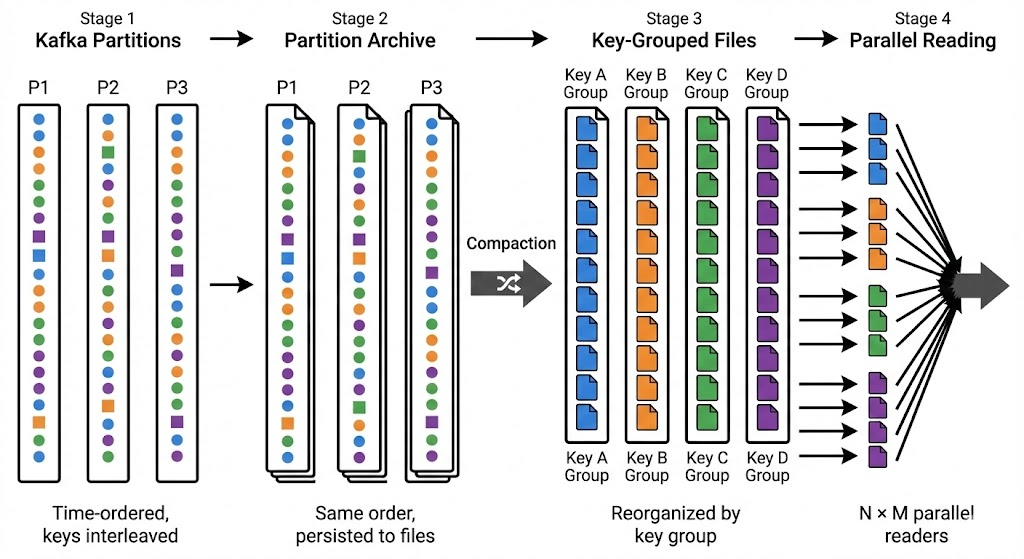
Instead of writing all keys to one file, or each key to its own file, we assign keys to a fixed number of key groups (e.g., 1000). Each key group gets its own file. Keys are mapped to groups deterministically (typically by hashingA hash function converts a key (like "user_12345") into a number. Taking that number modulo the group count gives you a group number. The same key always produces the same hash, so it always lands in the same group.), so a key always lands in the same group.
This addresses both constraints:
- Per-key ordering: Records for a given key are all in one file, in order. The guarantee is structural.
- Time coordination: Within each key group file, records are ordered by time (transactions are chronological). As you read through the file, all keys in that group advance through time together.
With 1000 key groups, this gives us:
- Parallel I/O. 1000 separate files. 1000 readers with no contention.
- Controlled file count. No small-file overhead, no listing latency explosion.
- Structural time coupling within groups. Keys in the same group can't race ahead of each other—it's physically impossible given how the file is ordered.
- Tractable cross-group coordination. Groups can race ahead of each other, so we need explicit synchronization. But coordinating 1000 groups is feasible; coordinating millions of keys isn't.
Load balancing across key groups
A simple approach assigns keys to groups via hashing. This distributes keys evenly by count, but not by volume—a few hot keysA "hot key" is a key with disproportionately high traffic. In a payment system, a popular merchant might have 1000× more transactions than an average user, creating a hot key that skews load distribution. can make one group 10× larger than others.
Remember the second constraint: time coordination. To prevent data from being incorrectly dropped as "late," readers across different groups must stay roughly synchronized. This means the system moves at the pace of the slowest group.
Load balancing by volume (using bin packing algorithms like Karmarkar-KarpThe Karmarkar-Karp algorithm is a classic approach to the "number partitioning problem"—dividing items into groups with roughly equal totals. It works by repeatedly combining the two largest items, producing near-optimal balance.) keeps groups within ~10-20% of each other, so no single group becomes a bottleneck.
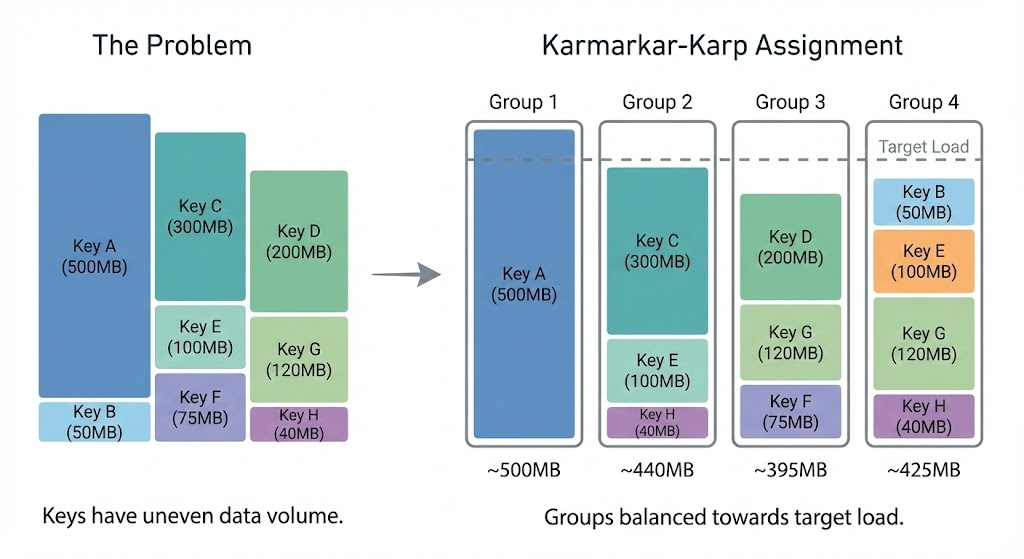
The payoff: With N Kafka partitions, traditional backfill gives you N parallel readers. With key groups, you get N × key-groups-per-partition parallel readers from the same source data.
This implementation layers on top of the traditional archiving approach—the original partition-ordered archive remains unchanged. Compaction produces a second representation optimized for parallel backfill, so existing systems that read the original archive continue to work.
Parallelism within a single source task
The problem is time coordination:
| Multiple Subtasks (distributed) | Single Task + Thread Pool (local) | |
|---|---|---|
| Watermarks | Each emits own; Flink takes min | One shared per task |
| When diverge | State bloats, watermark stalls | You control sync timing |
| Coordination | Across JVMs (network) | Local CyclicBarrier (memory) |
With distributed subtasks, synchronization requires coordination across JVMs—no shared memory,
no simple barriers. With internal threads, coordination is mandatory but trivial: all threads share
one output, one watermark, and a CyclicBarrier keeps them in lockstep.
The complexity stays contained in one place rather than distributed across the cluster.
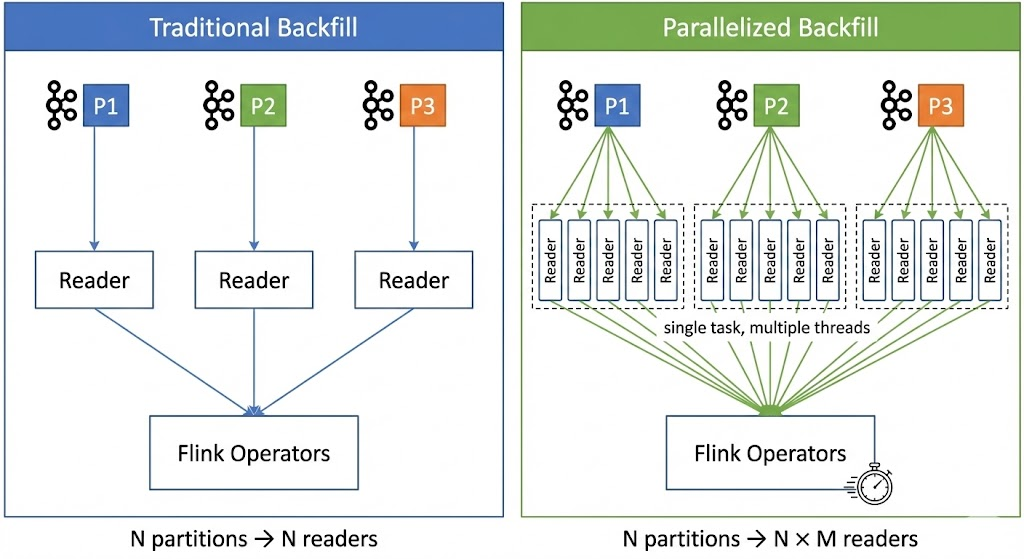
So we spawn many internal threads within each source task:
- Traditional: N partitions → N tasks → N sequential readers
- Parallelized: N partitions → N tasks → N × threads-per-task concurrent readers
Compaction architecture
This implementation layers on top of the traditional archiving approach—the original partition-ordered archive remains unchanged. Compaction produces a second representation optimized for parallel backfill, so existing systems that read the original archive continue to work.
Phase 1: Metadata collection
Before we can assign keys to groups, we need to know how much data each key contains. This requires a full scan of the archive transaction—but crucially, only to collect statistics, not to process records.
for each transaction in the archive:
for each record in the transaction:
key = extractKey(record)
bytesPerKey[key] += record.sizeInBytes()This produces a Map<String, Long> of bytes per keyWe use bytes rather than record count because I/O time is
proportional to data size—a key with 1GB takes roughly 10× longer to read than a
key with 100MB, regardless of record count., which feeds into the key-group
assignment algorithm.
Phase 2: Reorganization
With key-to-group assignments computed, we rewrite the archive. Each bucket of transactions produces a metadata file (key-to-group assignments, offsetsAn offset is a position marker in a stream—essentially "record number N." Storing offsets lets you resume reading from exactly where you left off after a restart.) and one Avro file per key group.
for each bucket of transactions:
writers[partition][keyGroup] = new Writer[NUM_PARTITIONS][NUM_KEY_GROUPS]
for each transaction in bucket:
for each record in transaction:
partition = record.partition()
key = extractKey(record)
group = keyToGroupAssignment.get(key)
writers[partition][group].write(record)
flush_all_writers()
write_metadata_file() Reader orchestration
At runtime, the compacted archive enables true parallel reading. The orchestrator spawns N reader threads, each responsible for a subset of key groups.
Reader Thread Distribution
Groups: 0, N, 2N..."] Orch --> T1["Thread 1
Groups: 1, N+1, 2N+1..."] Orch --> TN["Thread N-1
Groups: N-1, 2N-1..."] T0 --> Q["Work Queue"] T1 --> Q TN --> Q Q --> Out["Downstream Consumer"] style Orch fill:#fff9c4 style T0 fill:#81c784 style T1 fill:#81c784 style TN fill:#81c784 style Out fill:#c8e6c9
Round-robin assignment of evenly distributed key groups ensures balanced thread workloads
Key design decisions:
1. Work distribution: There exists a constant number of key groups evenly created key groups. These key groups are evenly divided assigned to each worker thread.
2. Barrier synchronization: Readers synchronize at transaction boundaries using a
CyclicBarrierA CyclicBarrier is a
Java concurrency primitive. When N threads call `await()` on a barrier, each one blocks
until all N have arrived. Then they all proceed together. "Cyclic" means it can be reused
for the next synchronization point.. All threads must complete their current
transaction before any thread starts the next one. This is how we enforce the second
constraint—time coordination. No reader races ahead, so watermarks advance uniformly and no
data arrives "late."
3. Batch processing: Readers consume records in small batches (e.g., 10 records) rather than one at a time. This amortizes queue overheadPutting items on a queue involves locking, memory allocation, and synchronization. Processing 10 items in one queue operation is cheaper than 10 separate operations—the fixed costs are "amortized" across multiple items. and improves cache localityModern CPUs are much faster than memory. When you access one memory location, the CPU loads nearby data into a fast cache. Processing records in batches keeps related data in cache, avoiding slow memory fetches..
Checkpointing & recovery
All of this parallelism is useless if you can't recover from failures. The tricky part: you now have N threads, each at a different position within their key groups.
Flink provides a robust checkpointing mechanism through its RichSourceFunctionRichSourceFunction is Flink's base class for custom data sources.
It provides lifecycle hooks (open/close) and access to runtime context. Combined with the
CheckpointedFunction interface, it enables exactly-once processing by persisting source
positions during checkpoints. and CheckpointedFunctionCheckpointedFunction is a Flink interface that lets operators
participate in checkpointing. It defines two methods: snapshotState() to save state during
checkpoints, and initializeState() to restore state on recovery. interfaces.
By implementing these interfaces, our parallel reader can leverage Flink's distributed snapshot
algorithm to achieve exactly-once semanticsExactly-once means each record is processed precisely once, even
after failures. Flink achieves this by checkpointing source positions and operator state
atomically, then replaying from the last checkpoint on recovery..
Per-key-group state
Instead of tracking one offset per partition (as a standard Kafka source would), we track one offset per key group per partition:
public interface KeyGroupReaderState {
// Which batch we're currently reading
String currentBatchId();
// Position within the current batch (record count)
long offsetWithinBatch();
// Have we caught up to this checkpoint position?
boolean caughtUpToState();
}
// Full checkpoint state for one partition
public interface PartitionReaderState {
KafkaTopicPartition partition();
KeyGroupReaderState[] keyGroupStates(); // one per key group
String batchStartTransaction(); // for resuming
}Snapshot logic
When Flink triggers a checkpoint, our source implements snapshotState() from the
CheckpointedFunction interface. Each key group reports its current position:
// Implements CheckpointedFunction.snapshotState()
@Override
public void snapshotState(FunctionSnapshotContext context) {
// Each reader thread saves its current position
List<KeyGroupReaderState> states = readerThreads.stream()
.map(reader -> KeyGroupReaderState.builder()
.batchId(reader.getCurrentBatchId())
.offset(reader.getRecordsRead())
.build())
.toList();
checkpointState.update(states);
}Barrier synchronization during checkpoints
All threads must finish each transaction before any thread moves to the next. Without this, two things break:
Problem 1: Checkpoint inconsistency. Our checkpoint state includes a
bucketStartTransaction that must be the same across all readers. If Thread 1 is on
transaction txn-100 while Thread 2 is on txn-50, which do we save? Pick
txn-100 and Thread 2 skips records on recovery. Pick txn-50 and Thread 1
reprocesses records. Either way, we violate exactly-once semantics.
Problem 2: Unbounded event-time divergence. Some key groups have more records than others. Without synchronization, a thread with sparse key groups races hours ahead in event time while a thread with dense key groups lags behind. Since all threads share one output, this breaks Flink's watermarkWatermarks are Flink's mechanism for tracking event-time progress. They flow through the pipeline, signaling "no more events older than time T will arrive." When all threads feed one output stream, the watermark advances based on what's been emitted—fast threads push it forward before slow threads catch up. semantics: the watermark races ahead based on fast threads, and slow threads' records arrive "late"—even though they're perfectly valid data—getting dropped from windows and aggregations.
We use Java's CyclicBarrier to enforce lockstep progress. The barrier is initialized
with a thread count—when that many threads call await(), they all unblock
simultaneously and the barrier resets for the next round:
class Orchestrator {
// N reader threads + 1 orchestrator must all reach await()
CyclicBarrier barrier = new CyclicBarrier(numThreads + 1);
void orchestrateReading(Stream<ArchiveBatch> batchStream) {
batchStream.forEach(batch -> {
// Distribute this batch's transactions to all reader threads
batch.transactions().forEach(transaction -> {
for (ReaderThread reader : readers) {
reader.workQueue().put(transaction); // BlockingQueue
}
});
// Wait for all readers to finish this batch
barrier.await();
});
}
}
class ReaderThread implements Runnable {
BlockingQueue<Transaction> workQueue = new LinkedBlockingQueue<>();
BlockingQueue<CompletedBatch> outputQueue = new LinkedBlockingQueue<>();
void run() {
while (running) {
// Process all transactions assigned to this thread
Transaction tx = workQueue.take();
List<Record> records = readMyKeyGroups(tx);
outputQueue.put(new CompletedBatch(records));
barrier.await(); // Signal "I'm done with this batch"
}
}
}Edge Case Handling extreme key skew
For most workloads, Karmarkar-Karp keeps key groups balanced enough that threads naturally progress at similar rates—transaction barriers are sufficient. But what about pathological key distributions?
Consider: 10 keys where one key holds 90% of the data. You can't split a single key across threads—that would violate per-key ordering. The best Karmarkar-Karp can do is assign the giant key to one thread and distribute the scraps to others. Within a transaction, threads with tiny keys finish in seconds while the thread with the giant key churns for much longer—plenty of time for event-time drift to cause problems.
For these workloads, I implemented proportional throttling: after reading
each batch, threads with smaller key groups introduce an artificial delay proportional to
(maxGroupBytes - thisGroupBytes). Threads with fewer bytes slow down; threads
with more bytes proceed at full speed.
// Throttle smaller key groups to prevent event-time drift
void processKeyGroup(Transaction tx, KeyGroup keyGroup) {
long maxGroupBytes = tx.getMaxKeyGroupBytes();
long thisGroupBytes = keyGroup.getByteSize();
while (keyGroup.hasMoreRecords()) {
List<Record> batch = keyGroup.readBatch(BATCH_SIZE);
outputQueue.put(batch);
long delayFactor = (maxGroupBytes - thisGroupBytes);
long delayMs = delayFactor * THROTTLE_CONSTANT / thisGroupBytes;
Thread.sleep(delayMs);
}
}This is a heuristic, not precise synchronization—it assumes bytes roughly correlate with event-time progression. But for pathological distributions where load balancing can't help, approximate synchronization is far better than none.
Limitations
This approach has real constraints:
- Bounded by partition count: With N partitions, only N source tasks do work—additional tasks sit idle. Adding more TaskManagers doesn't help at the source level.
- Single-node ceiling: Each task runs on one node, so you're bounded by that node's I/O bandwidth, CPU, and memory. You can scale vertically (more threads, bigger instance), but eventually hit the machine's limits.
- Escape hatch: If you need more throughput than one node per partition can deliver, you'd need to repartition with more Kafka partitions upstream—a bigger architectural change.
Within these constraints, the speedup is still dramatic: N sequential readers become N × M concurrent readers. For most workloads, the single-node ceiling is high enough that this approach transforms backfill from days to hours.
Conclusion
Historical backfill doesn't have to be slow. The bottleneck isn't inherent to historical data—it's an artifact of enforcing stronger guarantees than applications actually need.
The core insight: streaming applications require per-key ordering and coordinated time progression—but not per-partition ordering. Per-partition ordering is strictly stronger, and that unnecessary strictness creates the scalability bottleneck.
The solution layers multiple mechanisms:
- Key groups provide per-key ordering by assigning keys to files deterministically—each key always lands in the same group.
- Karmarkar-Karp load balancing keeps key groups roughly equal in size, so threads naturally progress through event-time at similar rates.
- A single source with internal threads keeps all coordination local—no distributed synchronization needed across the cluster.
- Transaction barriers ensure all threads finish each transaction together, providing clean checkpoints for exactly-once recovery.
The parallelism is local rather than distributed—all threads for a partition share one pod—but going from 1 sequential reader to many concurrent readers per partition is still transformative. Object storage handles parallel reads effortlessly.
The tradeoff is an upfront compaction cost. But for archives processed multiple times (migrations, reprocessing after bug fixes, new feature rollouts), this cost pays for itself quickly.
In production, this reduced backfill times from days to hours—transforming historical backfill from a dreaded operational event into a routine capability.